
Node Path
The web pages are usually presented as a HTML text. Web browser converts the web page text in the the
DOM (Document Object Model)
tree. For example, we have the HTML code:
<html>
<head>
<title>Test</title>
</head>
<body>
<div>Hello</div>
<div>World</div>
<span>
<div>
<img src='hello.gif'>
<img src='world.gif'>
/div>
</span>
</body>
</html>
which was converted by the web browser into the tree:
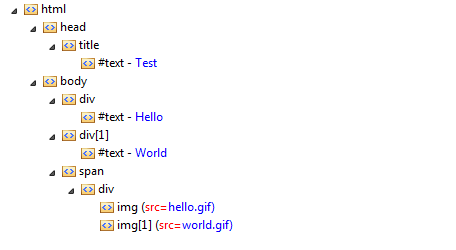
The Node Path
shows the way to any of the element from the DOM tree. To access the div
element containing the word World
we can use the following path:
html[0].body[0].div[1] or equivalent html.body.div[1]
The NodePath looks like the XPath but its syntax is different. The missing NodePath index is equivalent to the zero index. In XPath it is equivalent to any index.
Special symbols in the NodePath:
- * - any index or tag
- ... - any path
Examples:
- html.body.div[*] - path to 2 div nodes
- html...div[*] - path to 3 div nodes



